In these days I’m working on a complex migration from NAV to BC of a pharmaceutical environment. The customer is satified by NAV, the processes are very standardized and the database was kept clean, with no excess of coding in the base application.
So, why the migration is complex? Due performance issues! NAV and SQL Server was heavy optimized to support customer workload with techniques that are no more available. At the beginning of the project, in 2009, I had the pleasure to work with Hynek Muhlbacher and together we found the right compromise to start.
Many times we wondered if NAV was the right product for this business and maybe not for who scares about performance. Complete this job with BC, APPs and Universal Code seemed impossible.
The numbers
- More than 55.000 order lines per hour (via EDI)
- More than 25.000 availability and price requests per hour (via EDI)
- More than 1.600.000 shipment documents per year
- More than 800 GB of working database
- Plus 300 GB only for price lists
- Plus 1.600 GB for archived historical data
🤯
Before V23
I want to be honest: with previous data model it was impossible to migrate.
Some colleagues tried to execute the same invoicing process in BC and they was forced to come back, because 2 NAV hours had become 20 BC hours, with the system completely locked.
After V23
We are live since 3rd of october with all the financial processes with the whole amount of data. Invoicing process ends only few minutes after NAV. The system is always reactive, no stuck on flowfields and also the analysis view in the lists are fast.
Amazing!
Read Committed Snapshot Isolation
I wasn’t surprised when Microsoft announced V23 performance improvement. I can only imagine the abnormal CPU usage of Azure SQL Server in SaaS environments. Mabye some Microsoft DBA was heard and a fundamental feature (available since 2005!) has been implemented 😉
V23 performance gain doesn’t just comes from the “single companion table” which has been discussed a lot. It also comes from the new locking model that avoid the usage of UPDLOCK.
Microsoft called it “tri-state locking” and here is explained: https://learn.microsoft.com/en-us/dynamics365/business-central//dev-itpro/developer/devenv-tri-state-locking
The tri-state locking feature is aimed at enhancing the performance and concurrency of database transactions. By enabling this feature, AL-based read operations that follow write operations are performed optimistically, rather than with strict consistency and low concurrency. Consequently, users can expect higher levels of concurrency and fewer blocked or failed operations while accessing data.
As mentioned, this kind of locking is available in SQL Server since 2005 (!) but never used before. Its technical name is “multiversion concurrency control” (MVCC) and is implemented in SQL Server through “read committed snapshot isolation” (RCSI).
Here is the guide: https://learn.microsoft.com/en-us/dotnet/framework/data/adonet/sql/snapshot-isolation-in-sql-server
The READ_COMMITTED_SNAPSHOT database option determines the behavior of the default READ COMMITTED isolation level when snapshot isolation is enabled in a database. If you do not explicitly specify READ_COMMITTED_SNAPSHOT ON, READ COMMITTED is applied to all implicit transactions. This produces the same behavior as setting READ_COMMITTED_SNAPSHOT OFF (the default). When READ_COMMITTED_SNAPSHOT OFF is in effect, the Database Engine uses shared locks to enforce the default isolation level. If you set the READ_COMMITTED_SNAPSHOT database option to ON, the database engine uses row versioning and snapshot isolation as the default, instead of using locks to protect the data.
Please note that RCSI must be manually enabled in SQL Server. Without this flag, “tri-state locking” doesn’t work as expeceted.
ALTER DATABASE [My Database] SET READ_COMMITTED_SNAPSHOT ONDo not forget the code
So far, it seems amazing and simple. But the new features are useless without quality code. To get this level of performances, you need to know very well the Microsoft base application and the APP extensions must be perfect.
You need to avoid excess of queries, to use at its best the COMMIT, to use buffers for calculation and so on…
A little example. If you need to post huge amounts of data and concurrently use the system, you can skip several unnecessary MODIFY on the master tables. Currently we can’t do nothing to skip “Entry No.” locking on ledger tables (I can’t wait the moment when BC will use SQL SEQUENCE) but we can do much:
- Avoiding ITEM table locking to change “Cost Is Adjusted” flag during posting process
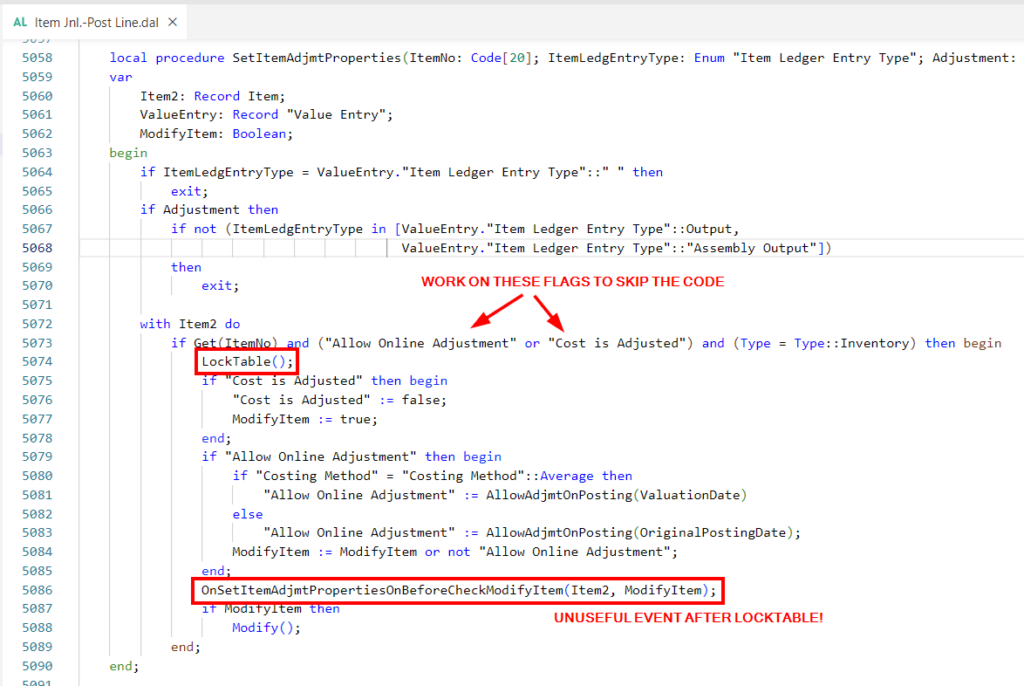
- Avoiding BIN table locking to set “Empty” flag

As said, these are only examples of the work you have to do to optimize the code.
Conclusions
If you are scared about the performance, you can’t work with huge customers. But these customers are really that can take out BC from the SMB area. The V23 release give you the tools to support big databases but AL code optimization is still fundamental.
And let’s be honest, with the right skills 😉 It’s satisfying to serve large business!